项目简介
OW2 contest program



说 明 书
![]()
基于流水线的高效可靠数据迁移方案
技术领域
本发明涉及一种高效可靠的数据迁移方案,特别针对大数据迁移,能够保证迁移前后数据的一致性,并且具有较高效率。
背景技术
近年来,随着计算机和信息技术的迅猛发展和普及应用,行业应用系统的规模迅速扩大,行业应用所产生的数据呈爆炸性增长。例如美国的纽约证券交易所每天大约会产生1TB的交易数据,互联网档案馆存储着约2PB数据,并以每月至少20TB的速度增长,视频分享网站Youyube上每天会上传的视频数据等。然而,不同时期的数据有不同意义,如对于大多数应用而言,刚生成的数据访问频率最高,而某些数据基本不会被访问。传统的单一数据存储和管理方式显然已经不能够满足海量存储以及性能需求;同时,对于某些海量数据存储中心,数据的访问具有很强的时间性和可预测性,对于某一时间阶段,需要访问同一部分数据多次,并且需要较高的数据访问速度。鉴于不同数据之间存在着显著的访问频率差异,采用不同访问速度和单位价格的多级设备构造分级存储系统显得非常合适,满足了存储容量和硬件成本约束的前提下,提供较高的访问性能。
对于这类应用,考虑将不同访问速率的磁盘结合,构造多层的数据存储方式具有非常重要的意义。如,将高速存储磁盘固态硬盘构成高速访问存储集群存储在线访问的数据,将低速存储磁盘机械硬盘构成低速廉价,大容量存储集群存储非在线访问的离线数据。目前许多数据中心就是采用这种方式存储数据。在这种分级存储系统中,数据的访问频率是动态变化的,为了使系统能够提供更好的性能,需要在不同的存储设备之间频繁的做数据迁移,然而统计显示,对于大数据的迁移会发生各类问题导致迁移失败或者迁移后的数据不可用。如,迁移过程中意外宕机;不同程度的数据丢失,数据的不一致等。所以,要保证大数据迁移前后的一致性,必须在数据迁移中和数据迁移后做一定的措施以保证迁移成功以及迁移后数据与迁移之前的数据一致。所以,一种高效的可靠数据迁移方案变的非常重要。
发明内容
本发明要解决的技术问题是:针对大数据分级存储中数据的迁移,迁移过程中由于许多的不可预知问题造成数据迁移的失败,或者迁移后的数据不一致,并且,数据迁移失败和不一致问题不容易检测出,检测数据迁移的失败或者数据的丢失非常困难,本发明提供一种可靠高效的数据迁移方案,通过在迁移中使用数据库记录数据状态和迁移完成后使用流水线进行MD5校验,避免数据迁移过程中意外导致的迁移失败或者丢失而造成的数据不完整,以及迁移完成后数据的不可用。
本发明的技术方案包括以下步骤:
步骤1、搭建大数据存储系统,以及数据访问接口,存储数据;同时初始化数据库,新建数据库和迁移任务管理表,初始化流水线数据单位缓存大小和数据缓存队列的大小;启动服务,扫描数据库中所有未完成任务状态,对每个未完成任务,从未完成状态重启任务,保证服务意外终止后数据的一致性;
步骤2、创建数据迁移任务;选择一个数据文件夹和目的路径,更新数据库,增加一条任务信息记录迁移任务需要记录的信息,准备将数据包含的所有文件迁移到对应目的路径;
步骤3、更新数据库,更改迁移任务状态信息为计算源文件MD5状态,并开始使用流水线方式计算源数据文件的MD5值;由于计算源文件MD5值需要将源文件每个位读取出来并做计算,主要的时间消耗是读取文件内容的I/O时间消耗和计算MD5值的CPU时间消耗,显然读取文件内容和计算MD5使用的计算机资源并不相同,则使用多线程流水线的处理能够很大的提升性能,具体步骤与4中相似;
步骤4、计算源文件MD5值结束后,更新数据库,记录源文件MD5值信息,更改任务状态信息为开始迁移状态,开始流水线迁移数据文件并计算目的文件MD5值;由于迁移文件需要将源文件所有内容全部读出到缓存中,然后将缓存写入目的文件,则目的文件的内容都是通过缓存文件写入的,所以,可以通过缓存中的内容直接计算出目的文件的MD5值,而不需要迁移完成后再次读取目的文件,再计算MD5值,可以很大的提升性能,同时,和计算源文件MD5相似,读取源文件到缓存,将缓存写入目的文件,累计缓存中的MD5值,三个步骤采用流水线并行化操作,可以很大的提升性能;具体步骤参见步骤41到步骤44;
步骤5、迁移结束后,对比源文件的MD5值和目的文件的MD5值,如果相同,则更新数据库,更改数据迁移状态为迁移成功,结束,否则进行步骤6。
步骤6、迁移失败,数据回滚,即如果目的文件存在,则删除目的文件,避免脏数据的产生,更新数据库,更改数据迁移状态为迁移失败。
步骤4中所述的具体执行以下步骤:
步骤41、更新数据库中,记录下步骤3中计算的源文件MD5值,更改任务的状态信息为正在迁移状态,初始化未使用,写入,计算MD5三个缓存队列,并将读取缓存中装满已经申请好的缓存对象(这样可以增加流水线的灵活性,避免频繁申请缓存以及单缓存造成的进程频繁切换造成的时间损失),启动读取,写入,计算MD5 三个进程;
步骤42、从未使用缓存队列中取一个缓存对象,如果队列为空,则阻塞读取文件进程,等待申请到未使用缓存对象,将缓存对象传递给读取进程,读取源文件一部分内容到缓存中,如果源文件已经读取结束,结束读取进程,否则,将缓存对象放入写入缓存队列中,如果写入缓存队列已满,则阻塞等待;
步骤43、从写入缓存队列中取一个缓存对象,如果队列为空,并且读取进程已经结束,则结束写入进程,否则阻塞直到取到一个缓存对象;将缓存中的内容写入目的文件,并将缓存对象放入计算MD5缓存队列,如果计算MD5缓存队列已满,则阻塞等待;
步骤44、从计算MD5缓存队列中取一个缓存对象,如果写入缓存队列和读取缓存队列都为空,并且写入进程和读取进程都已经结束,则结束计算MD5进程,返回MD5值,该步骤执行完毕;否则阻塞直到取到一个缓存对象;计算并更新缓存中的内容的MD5值,然后清空缓存并将缓存对象放入计算读取队列,如果未使用缓存队列已满,则阻塞等待;
采用本发明可以达到以下技术效果:
本发明适用于大数据文件的可靠性快速迁移,提供一种有状态的迁移方式保证大数据文件迁移过程中的数据一致性,避免迁移过程中的机器宕机,服务意外终止等情况产生的不完整数据文件,同时提供一种基于流水线方式高效的数据文件校验方法,避免数据文件迁移中数据的丢失导致的数据不一致性。
附图说明
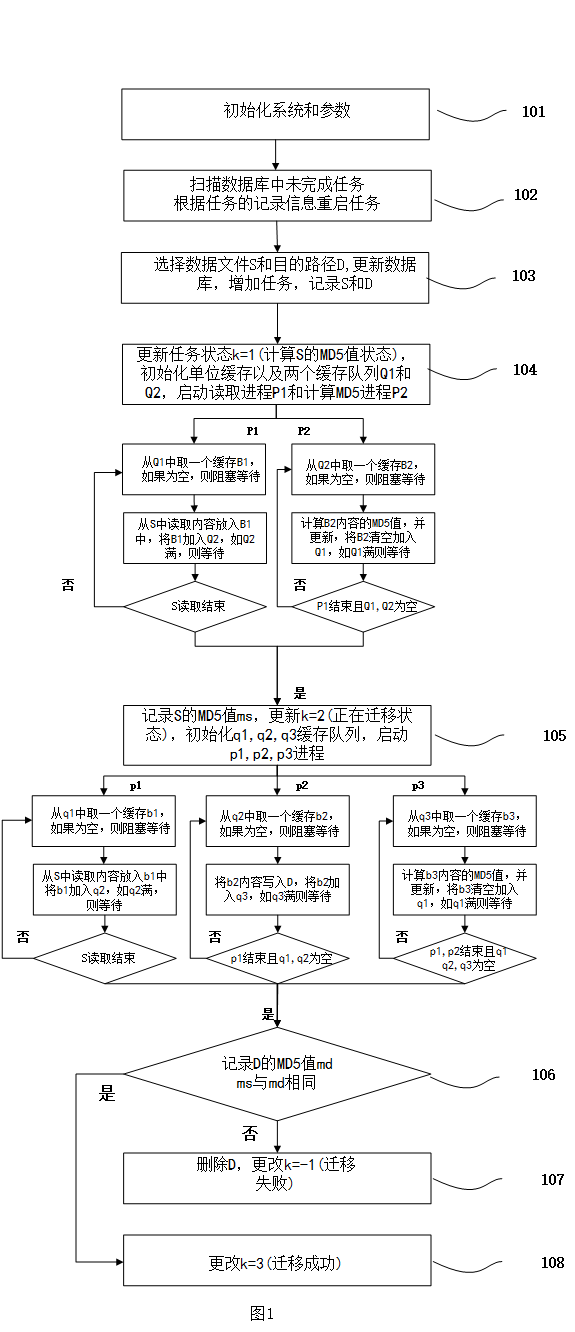
图1为本发明数据文件迁移校验流程图;
具体实施方式
步骤101、初始化数据库Database以及任务管理表TaskInfo,设定服务最优参数,单位缓存的大小BufferSize和缓存队列的大小QueueSize;
步骤102、扫描TaskInfo中状态未在终止状态的任务即k等于1或者2,从该状态重启任务,防止服务意外终止等导致的数据不一致;
步骤103、选择相应的数据文件S和目的路径文件D,更新数据库,增加一条任务记录,记录S到D的数据迁移必要信息;
步骤104、更改任务状态k=1,表示正在计算源文件S的MD5值;用QueueSize初始化两个缓存队列读取缓存Q1和计算MD5缓存Q2,用BufferSize大小的缓存填满Q1,启动两个进程读取进程P1和计算MD5进程P2,开始计算源文件MD5值,即同时进行步骤1041和步骤1043;
步骤1041、P1-1:从Q1读取缓存队列中取出一个缓存对象B1,如果Q1为空则阻塞等待直到取到B1;
步骤1042、P1-2:将源文件S中读取BufferSize大小的内容M,如果S读取完成,则P1结束;否则将读取到的内容M放入缓存B1中,将B1加入Q2队列,如果Q2已满,则阻塞等待直到加入成功,重复步骤1041;
步骤1043、P2-1:从Q2计算MD5缓存队列中取出一个缓存对象B2,如果Q2为空则阻塞等待直到取到B2;
步骤1044、P2-2:计算B2内容的MD5值,并更新,将B2清空加入Q1,如Q1满则等待;如果Q2为空且P1结束则返回源文件S的MD5值ms,P2结束,否则重复步骤1043;
步骤105、更新数据库,记录步骤104计算出的源文件S的MD5值ms,用QueueSize初始化三个缓存队列读取缓存q1,写入缓存q2和计算MD5缓存q3,用BufferSize大小的缓存填满q1,启动三个进程读取进程p1,写入进程p2和计算MD5进程p3,开始迁移文件并获取目的文件MD5值,即同时进行步骤1051,步骤1051和步骤1053;更改任务状态k=2,表示正在进行数据迁移;
步骤1051、p1-1:从q1读取缓存队列中取出一个缓存对象b1,如果q1为空则阻塞等待直到取到b1;
步骤1052、p1-2:将源文件S中读取BufferSize大小的内容M,如果S读取完成,则p1结束;否则将读取到的内容M放入缓存b1中,将b1加入q2队列,如果q2已满,则阻塞等待直到加入成功,重复步骤1051;
步骤1053、p2-1:从q2写入缓存队列中取出一个缓存对象b2,如果b2为空则阻塞等待直到取到b2;
步骤1054、p2-2:将b2中的内容写入目的文件D中,将b2加入q3,如q3已满则等待;如果q2为空且p1结束则返回写入完成,p2结束;否则重复步骤1053;
步骤1055、p3-1:从q3计算MD5缓存队列中取出一个缓存对象b3,如果q3为空则阻塞等待直到取到b3;;
步骤1056、p3-2:计算b3内容的MD5值,并更新,将b3清空加入q1,如q1满则等待;如果q2,q3为空且p1,p2结束则返回目的文件D的MD5值md,p3结束;否则重复步骤1055;
步骤106、更新数据库,记录步骤105中计算的目的文件MD5值md,比较目的文件MD5值md和源文件MD5值ms是否相同,如果相同,则进行步骤108;否则进行步骤107;
步骤107、数据校验失败,迁移前后数据不一致,删除目的文件D,更改任务状态k等于-1,表示迁移失败;
步骤108、数据校验成功,更改任务状态k等于3,表示迁移成功。
最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围。
论文基于数据在不同volume上面的迁移后校验为基础,设计了三种方案:
- 迁移前计算源文件MD5,迁移完成后计算目的文件MD5,然后校验;
- 计算源文件MD5,迁移中同时计算目的文件的MD5值,完成迁移后校验;
- 设计流水线的方式计算源文件MD5和迁移并计算目的文件MD5,完成后校验。
对于三种方式,分别实验,分别对于低速数据卷 L 到 高速数据卷H,以及H>L, H>H,L>L
对于不同大小文件效率:
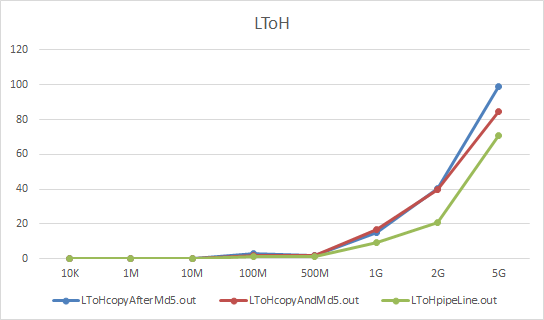
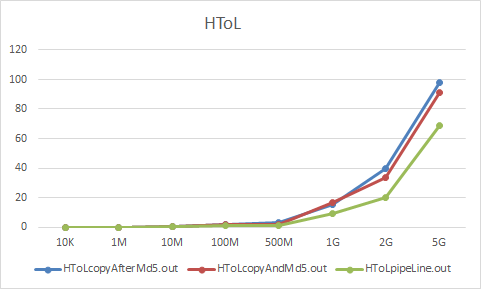
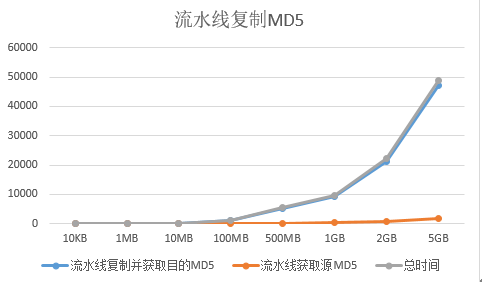
以及其他两个数据,变化趋势基本相同。流水线方式对于性能有较好提升。
流水线方式的优化:
流水线方式复制文件和获取MD5值方式对于流水线的粒度和流水线缓冲队列长度优化数据:
这是LToH的优化数据
其中行表示缓存粒度,列表示缓存队列长度,由这数据可以得出流水线的最优参数。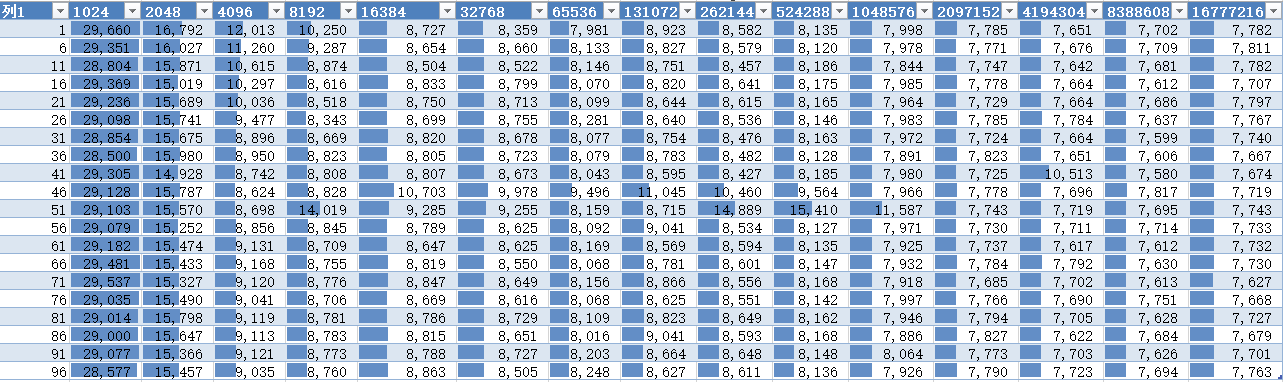
还有对于glusterfs io/cache使用对效率的影响:主要是获取源文件MD5值的影响,因为获取源文件MD5值时候已经读取过源文件了,此时如果缓存大小合适,则缓存命中,读取速度回大幅度提升,(用于高速网络),如L>L 的流水线模式比较:
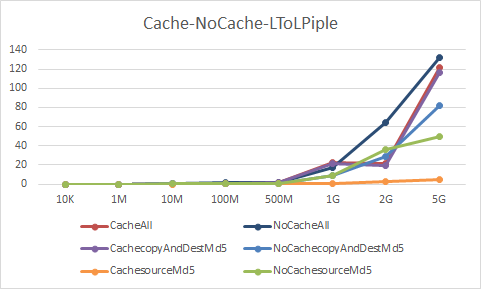
显然对于第一次读取有一定的效率下降,但第二次读取效率提升明显,总的效率有一定提升
说 明 书
![]()
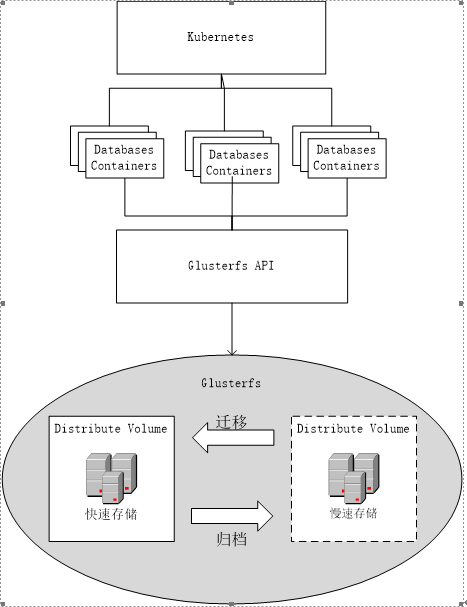
一种高可用数据文件分布式存储系统
技术领域
本发明涉及一种基于Glusterfs的分布式存储方法,特别针对于具有高速在线和低速离线备份双存储的以文件夹为整体的数据存储。
背景技术
近年来,随着计算机和信息技术的迅猛发展和普及应用,行业应用系统的规模迅速扩大,行业应用所产生的数据呈爆炸性增长。动辄达到数百TB甚至数十至数百PB规模的行业/企业大数据已远远超出了传统的计算机存储能力,因此,分布式存储的使用已经越来越普及。
Glusterfs是目前较为成熟的开源分布式存储软件。是一个支持PB级数据存储的无元数据服务器分布式存储系统,支持线性性能扩展,解除对元数据服务器的需求,消除了单点故障了性能瓶颈,真正实现了并行化数据访问。
对于许多大数据应用而言,不仅需要存储数据,还需要快速的切换和访问需要的一部分数据。目前的数据访问瓶颈大部分仍然是磁盘性能,所以,对于高速访问基本采用SSD固态磁盘,但是SSD的代价比普通机械硬盘HDD高许多,而HDD又不能满足高速访问的要求,对于一个拥有海量数据,并且某一时间段内,只需要访问一部分数据的应用而言,全部使用SSD和或者全部使用HDD都是不合理的。对于此类应用,可以构建一个拥有两个数据卷的Glusterfs分布式存储集群,高速访问区用SSD构建高速分布式集群Distributed数据卷,低速数据备份存储区选择HDD构建一个低速廉价分布式集群Distributed数据卷。在未来一段时间内需要频繁访问某个数据时候,可以将数据从HDD数据卷迁移到高速SSD数据卷,数据使用完成后,再将数据从SSD数据卷备份到HDD数据卷。
在集群中,存储的是数据文件夹,其中的文件会分布存储在不同的节点上,这样数据的完整性无法保证,一旦一个节点出现故障,几乎所有的数据文件夹可能都会缺少文件,造成所有的数据文件夹损坏不可使用,这是不能容忍的。但是由于高速数据卷采用SSD做存储介质,代价比较昂贵,而Glusterfs的replicated数据卷的存储利用率非常低,如果用replicated会使存储利用率下降到50%一下,并且一旦两个节点损坏,仍然有丢失所有数据文件夹的可能,所以这样的方案不可行,需要一个替代方案能够满足一下要求:
1. 存储利用率高,由于SSD代价非常高,不能以较大的牺牲存储保证数据安全性。
2. 数据是相对安全的,一个节点的故障不能影响其他节点的数据,高速存储区中的数据在低速廉价存储区都有备份,少量的数据文件夹的丢失可以接受,只需从新从低速存储区再复制一份即可。
3. 不会对数据的访问和存储速度造成较大影响。
目前还没有一个完整的存储方案能够满足以上要求,Glusterfs的是基于弹性Hash算法定位文件,所以文件的分布具有随机性,对于同一个整体数据文件夹中的文件不能保证存储在同一节点上,而这种整体数据文件夹中文件损坏或者丢失一个,整体数据文件夹即损坏。所以,需要一种能够将整体文件夹中的文件存储在同一节点上的高可用分布式存储系统。
发明内容
本发明的目的在于针对现有存储技术的不足,针对整体数据文件夹的高效可靠存储的需求,提出的基于Glusterfs分布式存储的以文件夹为单位分布的高效可靠分布式存储系统。
本发明的技术方案包括两个方面,数据文件夹的存储和集群节点变化的处理负载均衡。
1. 数据文件夹的存储:
步骤1、搭建集群并创建数据卷;
步骤2、在数据卷中创建数据文件夹,具体步骤参见21-24;
步骤3、根据数据文件的文件名计算hash值,并根据父目录的hash分布获取其hash卷;
步骤4、在对应hash卷上创建文件。
2. 子卷变化的数据均衡:
步骤5、查看所有节点可用容量是否超过配额(用户可以设置)。
步骤6、如果没有超过配额,则不处理,如果超过配额,则对于该子卷上的所有数据文件夹重新查找最优子卷,设置数据文件夹hash区间在该节点;
步骤7、对于文件夹中的每个文件,在新节点下创建链接,链接到源文件夹中的每个文件。然后开启数据复制,将源文件复制到新文件夹下。
步骤8、复制完成后,将链接指向新文件,并删除源文件,数据迁移完成,进行下一个数据文件夹迁移,直到容量大于配额设置。
步骤2中所述的具体执行以下步骤:
步骤21、在父目录的所有子卷中创建目录;
步骤22、目录的名如果等于统一存储目录名(用户配置),则进行24;否则,进行23;
步骤23、为每个子卷在该目录上平均分配hash区间,并记录在扩展属性中;
步骤24、寻找最优子卷,将最优子卷hash区间定为最大,其他子卷定为0,并记录在扩展属性中。
采用本发明可以达到以下技术效果:
在基于Glusterfs的分布式文件存储系统中,配置的特定文件名称,该文件名下的所有的文件都会分布在同一子卷上。以保证Glusterfs某个子卷损坏的情况下,其他子卷上的数据文件夹可以正常使用,成功的解决了Glusterfs一个子卷损坏会使所有数据卷中数据失败的问题。同时,由于数据卷子卷的增加可能会引起数据分布的不均衡,新子卷负载教轻,原子卷负载较重,通过数据的重新均衡,以解决子卷数据不均衡问题。
附图说明
图1为本发明数据文件夹的存储的流程图;
图2为本发明数据卷子卷发生变化时候,数据重新均衡的流程图;
具体实施方式
本发明主要针对基于Glusterfs分布式存储系统的数据文件夹的存储。
如图1所示,为本发明数据文件夹的存储流程图,具体执行以下步骤:
步骤 101、搭建一个Glusterfs集群S,并创建包含A,B,C三个子卷的数据卷D,准备在D中存储testFolder数据文件夹;
步骤 102、在所有子卷A,B,C上创建数据目录testFolder;
步骤 103、如果testFolder等于用户配置的特定统一分布目录名称FolderName,则进行105,否则进行104;
步骤 104、在A,B,C上的testFolder平均分配Hash区间。
步骤 105、在A,B,C上的寻找最优的子卷A,将所有Hash区间分配到A上的testFolder,其他B,C上的目录Hash区间为空;
步骤 106、在A,B,C上的testFolder目录扩展属性中记录分配到的Hash区间;
步骤 107、根据数据文件夹中某个文件testFile文件名计算Hash值m;
步骤 108、根据hash值m以及父目录记录的hash区间,确定文件testFile的子卷A;
步骤 109、子卷A的testFolder下面创建文件testFile;
该方案是针对指定数据文件夹中的多个文件需要整体存储,需要更改数据文件夹中的hash区间分配,将Hash区间分配在一个子卷上,保证该数据文件夹下所有文件能够存储在一个子卷上,保持集群的高容错性。
如图2所示,为本发明在数据卷子卷发生变化时候,对于数据的重新均衡流程图,具体执行以下步骤:
步骤 201、数据卷X子卷发生变化,添加子卷D,并启动数据均衡;
步骤 202、扫描X中子卷A的可用容量S;
步骤 203、S是否超过限额Z,如果是执行204,否则执行209;
步骤 204、随机获取存储在子卷A中的一个数据文件夹E;
步骤 205、寻找一个最优子卷D,并将A中E的目录Hash区间设置成0,将D子卷中A中E的hash区间设置成全部;
步骤 206、在D中E目录下创建一个LINKFILE文件,记录E中每个文件目前的子卷A;
步骤 207、将E中的所有文件从A复制到D;
步骤 208、复制完成后,将LINKFILE中记录更改成迁移后的子卷D,然后删除A子卷中E下的文件,重复203;
步骤 209、是否扫描过X中的所有子卷,如果是执行210,数据均衡结束,如果不是将A指向X中的下一个子卷,重复202;
步骤 210 数据均衡结束;
最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围。
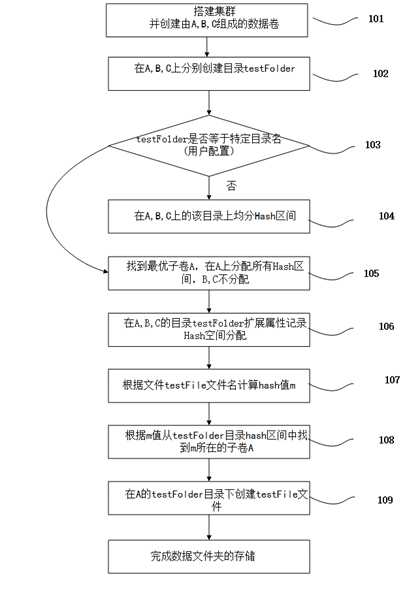
图 1
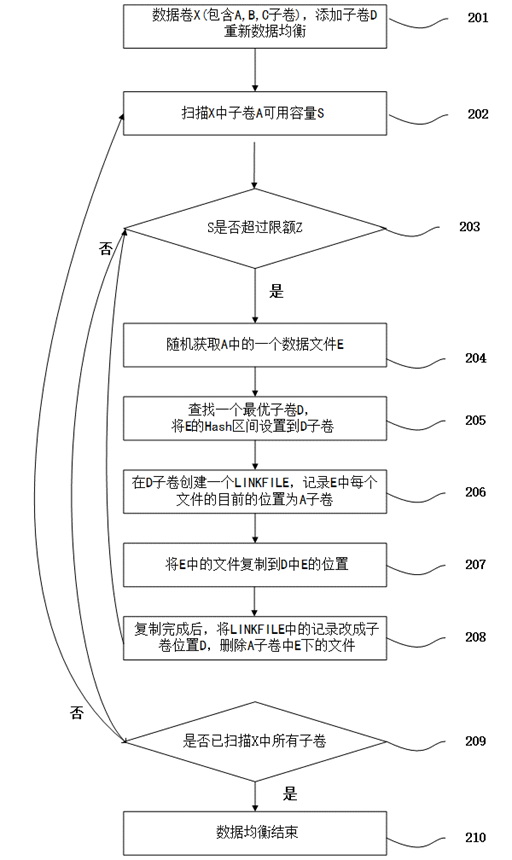
图 2
MD5 校验和(checksum)通过对接收的传输数据执行散列运算来检查数据的正确性[1]。一个散列函数,比如 MD5,是一个将任意长度的数据字符串转化成短的固定长度的值的单向操作。任意两个字符串不应有相同的散列值(即,有“很大可能”是不一样的,并且要人为地创造出来两个散列值相同的字符串应该是困难的)。一个 MD5 校验和(checksum)通过对接收的传输数据执行散列运算来检查数据的正确性。计算出的散列值拿来和随数据传输的散列值比较。如果两个值相同,说明传输的数据完整无误、没有被窜改过(前提是散列值没有被窜改)。
我们可以使用MD5保证数据的完整性和可用性。对迁移前后的数据做MD5校验,如果校验一致,则表示数据文件相同,迁移成功;如果校验不一致,则表示数据出错,迁移失败,删除迁移的数据。
1. 迁移后分别获取源文件和目的文件的MD5值
首先做文件的迁移,待迁移完成后再分别获取源文件和目的文件的MD5值,进行校验。过程如下:
1) 进行数据迁移,包括两个步骤:
a) 读取源文件数据;
b) 写入目的文件数据。
2) 判断数据迁移是否成功,如果失败,进行6,如果成功,进行3;
3) 获取源文件的MD5值:
a) 读取源文件字节;
b) 计算源文件字节MD5值;
4) 获取目的文件的MD5值:
a) 读取目的文件字节;
b) 计算目的文件字节MD5值;
5) 校验源文件MD5与目的文件MD5是否相同,如果相同,则结束;否则,进行6;
6) 删除目的文件。

|
测试文件大小 |
复制文件时间/ms |
获取源文件MD5时间/ms |
获取目的文件MD5时间/ms |
总时间/ms |
|
10KB |
8.4 |
3.2 |
2.8 |
14.4 |
|
1MB |
1.8 |
56.2 |
4.8 |
62.8 |
|
10MB |
16.8 |
33.6 |
33.4 |
83.8 |
|
100MB |
134.8 |
303 |
301.8 |
739.6 |
|
500MB |
404 |
1483.8 |
1489.8 |
3377.6 |
|
1GB |
863 |
3026 |
3041 |
6930 |
|
2GB |
1659.6 |
6087.4 |
6105.8 |
13852.8 |
|
5GB |
7109 |
15208.4 |
15262 |
37579.4 |

2. 迁移同时获取目的文件的MD5值
由上面的分析结果可知,花费的总时间由3部分组成,数据文件复制时间,获取源文件MD5和获取目的文件MD5,显然,获取源文件和目的文件Md5
|
测试文件大小 |
复制文件并获取目的MD5时间/ms |
获取源文件MD5时间/ms |
总时间/ms |
|
10KB |
10 |
3 |
13 |
|
1MB |
57.4 |
4.8 |
62.2 |
|
10MB |
43.2 |
35.2 |
78.4 |
|
100MB |
351.2 |
308.6 |
659.8 |
|
500MB |
1451.4 |
1497.4 |
2948.8 |
|
1GB |
3016.8 |
3051.2 |
6068 |
|
2GB |
5964 |
6076.4 |
12040.4 |
|
5GB |
14855.6 |
15186.8 |
30042.4 |
统计图:

参考文献
[1] http://baike.baidu.com/link?url=aPFRGzg3ahwIVemHU8-VEHR2uWjmU2r8SUlGePPP4x6OE-lgDbUN_tTNcVpu2cF6sPC_yvhDKz_GwppgTk12KtVG1NsVlte_0DEgsu_h61K
[2] Fasfas
对于数据迁移实验方案
目前采用方案:
目前采用的冷热区之间数据的迁移是通过fuse访问集群数据,复制文件夹,复制完成后为保证数据完整性,再做MD5校验。
缺点:
复制文件需要将文件读取一次,再写入一次,然而MD5校验也需要将文件读取一次,需要校验MD5则需要获得源文件和目的文件的MD5值,需要再读取一次源文件和目的文件,对于大数据文件时非常耗时间的。
同时,对于整个数据文件夹,一旦一个文件校验失败,整个文件夹则不可用,需要删除,所以,拷贝完成再次校验还有一个问题是,一旦出现拷贝失败的情况不能及时察觉。
改进方案:
对于文件的复制和校验,可以并行进行。在复制文件读取的过程中,同时计算MD5值,与源文件Md5值进行比较,校验。一个文件复制完成就开始校验,避免复制整个文件夹后校验失败的时间消耗。测试与之前方案的性能改进。
改进方案优化:
对于文件的读取,java可以设置缓存,然而对于不同的文件类型,不同的文件读取方式,缓存的选择等,都对文件的读取效率有一定的影响,可以通过实验,对比不同方式的影响,选择对应数据最佳的文件读取方式。
使用Glusterfs libapi改进:
目前的方案都是基于fuse读取文件,相当于在glusterfs 外边再次包装一层,使用fuse会降低glusterfs 文件读取效率,所以从glusterfs 3.4就开始提供了libapi的数据访问方式,可以不经过fuse,提高文件访问效率。
但是,libapi目前只有c语言的和最新版本提供了python的调用,没有java调用接口,实际应用可能需要用java 去调用c的libapi接口,然后对比。
论文架构说明
1. 引言
由旧的数据采集方案(如图1)
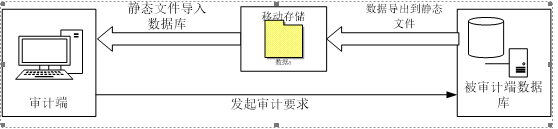
图1
引入新的数据采集方案图2
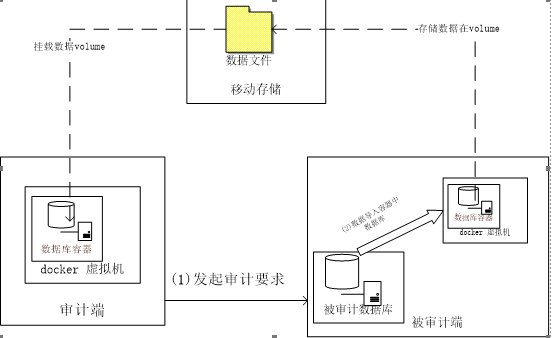
图2
引入新的采集方案的存储问题,以及存储方案。